Writing in the Journal of International Business Studies Klaus Meyer and his colleagues outline some problems in academic research. The authors tell us how they suggest dealing with the problem.
Familiar Problems In Academic Research
The problems they outline will be quite familiar to anyone following recent controversies in academia. The file drawer problem is well-known. Researchers conduct many studies. Yet, only the ones that turn out well tend to be published. Given results can, and do, occur by luck if enough people test any hypothesis someone is going to find a positive result. These will occur even if merely by total chance. A researcher can much, much more often publish positive than negative results. As a result, we end up with published significant results for any number of theories many of which seem to directly contradict each other.
P-Hacking
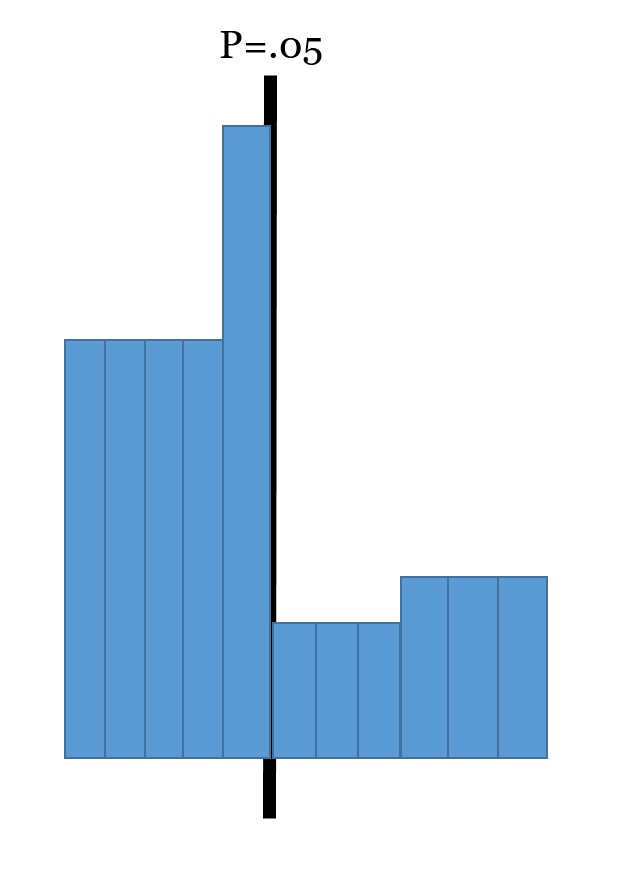
The authors do a graph of findings in a number of major management journals. (There are similar graphs for other journals). They show a relatively smooth curve. Yet, there is a bizarre pattern at around p=.05. This is completely inconsistent with the rest of the graph. P<.05 is often used as the level where things are significant. As such, there exist clear incentives for academics. Studies with significance under p=.05 are very different to those with ps just above .05. Lots of paper miraculously seem to just beat .05.
The combination of a spike just above the p-value of 0.05 and the valley just below in the distribution of p-values close to the critical value of 0.05 (critical from a reporting point of view) corresponds with similar findings in economics and psychology.
Meyer, van Witteloostuijn, Beugeldijk, 2017, page 539
So, how could this come about? Scholars have many methods to (consciously or unconsciously) influence the findings. For instance, they often decide what participants were not valid. For example, those not paying sufficient attention are not therefore valid. The academic can choose to drop “outliers”. Any time you give researchers discretion runs the risk of reported results happening to be better than they would normally be. (This is even without scholars just making up results). In conclusion, be careful. Academic results might not be as definitive as they seem.
Post-Hoc Theorizing
…scholars often conduct many tests, and develop their theory ex post but present it as if the theory had been developed first.
Meyer, van Witteloostuijn, Beugeldijk, 2017, page 539
This is HARKing. (The term stands for hypothesizing after the results are known). It is similar to placing the target after you have fired the arrow. Unsurprisingly, you tend to find something significant if you do this.
To cut down on poor (or even sometimes plain fraudulent) research methods the authors have a number of suggestions. Radically these involve dropping the reporting of cut-off significance levels to avoid any fixation on p=.0.5. I have sympathy with such changes that are coming to academic research. They won’t correct all problems. Yet, they are, however, probably a step in the right direction.
For more on problems in academic research see here, here, and here.
Read: Klaus E Meyer, Arjen van Witteloostuijn, and Sjoerd Beugelsdijk (2017) What’s in a p? Reassessing best practices for conducting and reporting hypothesis-testing research, Journal of International Business Studies, 48 (5), pages 535-551