
Scott Hartshorn has some useful accessible advice on all things analytics. Today I’ll look at his advice on random forests and machine learning.
Machine Learning
He starts by giving us a clear intuitive, rather than a formal, view of what machine learning (ML) is. He says that at their heart a lot of different ML models are designed to do the same thing.
…start with examples of something that you know, and use those to develop a pattern so you can recignize those characteristics in other data that you don’t know as much about.
Scott Hartshorn, not dated, page 8
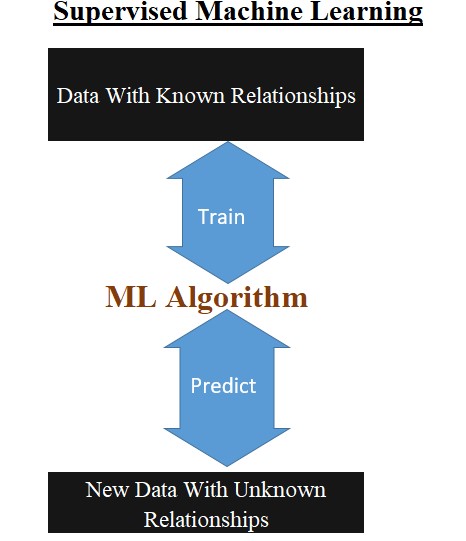
This is a useful way of looking at it. I think we should probably recognize that a lot of machine learning can be exploratory. As such let us refine this to say this describes best ‘supervised machine learning’. You use the approach above when you already have a clear goal — e.g., to find out what predicts university success.
A Random Forest
A method used in understanding data is the random forest which Hartshorn explains in his book. Imagine that you might want to classify some data. Almost any data can be classified. For example, you can classify customers into those who are more or less profitable. You can classify products as to those that solve particular needs. You can classify competitors according to those consumers see as more similar to each other. A random forest creates decision trees as to how to do the classification. To return to our example in order to predict success in an MBA program you might start with an undergraduate GPA, or you might start with GMAT score, or undergraduate alma mater; anything really.
A problem with such models is that there are many choices that can be made. You can have a massive amount of different ways to create the decision tree. A random forest creates lots of different possible trees. Some might ignore features — to see if it matters if you ignore them, i.e., changes the tree a lot. Other trees might use different combinations/orders of features. These trees are then combined by some sort of voting method.
Checking The Model
Is the model you end up with any good? One of the things that you can do with the models is cross-validation. You leave out some of your data from the model estimation. This is treated like new data. You can then use the model trained on the first part of the data to predict the data you haven’t used. You can get an idea of how good your model is at prediction.
Overfitting
A model that does great on the data it is trained on but not well on new data is known as overfitted. Basically, you have a model that knows the data you gave it very well. It likely reacts to the random quirks in that data. Still, because it reacts to all the random quirks unique to the specific data that it was trained on it has learned rules that don’t apply widely. An overfitted model isn’t useful for predicting beyond its specific data set. (So isn’t generally very useful). For more on this see here.
I appreciate these sort of short books that explain complex ideas in easily digestible ways. For more from Scott Hartshorn see here. Also, see my discussion of one of his other books — on Bayes Theorem.
Read: Scott Hartshorn (nd) Machine Learning With Random Forests And Decision Trees: A Visual Guide For Beginners